A cleaner way to design an IDE
In part 1 I talked about how modern IDEs look like this:
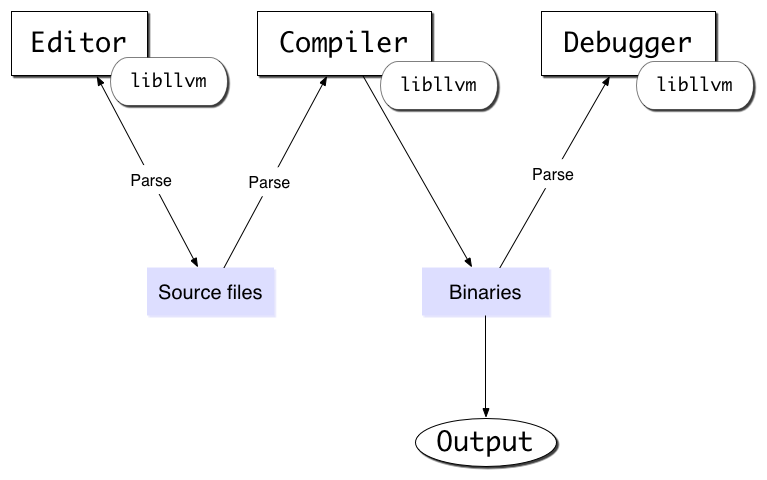
There are some serious problems with this model:
- The code needs to be parsed in several places.
- When the code changes, the binaries need to be recompiled. Triggering this recompilation requires either:
- Manual recompilation (at the worst possible time!)
- Special code in the IDE to be constantly triggering the compiler as I type (like Eclipse)
- Filesystem hooks to detect changes to the source files and a watcher process. Tup is probably the best example here. However, these only have a granularity of a file changing. They can't react to a single line of code changing.
- With the exception of pre-compiled headers, all of the compiler's intermediate state must be regenerated between builds. This is particularly bad for languages like C++. Go was specifically designed around this architectural weakness in our tooling.
- The editor needs special language support. Most editors that support multiple languages do a terrible job understanding the semantics of any language. (I'm looking at you, vim).
- Adding editor integration for custom tooling / workflows are super hard to write and usually brittle. For example, you might want to integrate your unit test runner into your IDE. There's no way to do this in a cross-IDE manner today. And how do I pair program? Without specific IDE support, its impossible.
So how do we fix this?
I've been thinking about this for the last few years and I think I have a decent way to clean up this mess.
First, I think we need to share the source code between all the components of the IDE. This shared source code should be annotated by the compiler to show syntax highlighting and autocomplete suggestions.
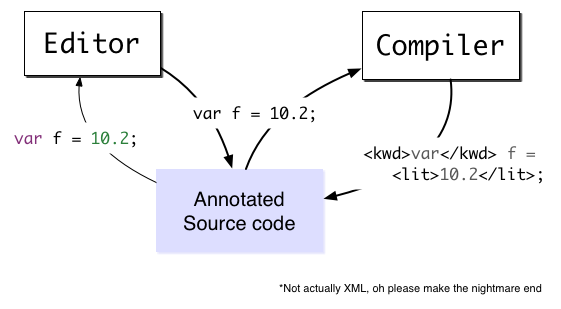
The obvious solution of baking the whole IDE into a single process would be a terrible idea. And if all the components used shared memory, we'd need a standard ABI to let them modify the data. This would need to be as extensible as the components themselves; a hard problem. But its harder still because compilers are usually written in their own language, and we need to support that.
Its a little tempting to grab something off the shelf and run a distributed shared memory system. But the data is structured, not binary bytes. And we want offline support and local speculative editing. And pair programming.
My dream IDE
It turns out, there's a perfect tool for this shared memory problem. I think we should put all the project source into an operational transform system. This lets you do some really neat stuff that we can't do otherwise, and it fixes all of the problems above. (I'm sure it'll introduce new problems too, but it wouldn't be fun otherwise).
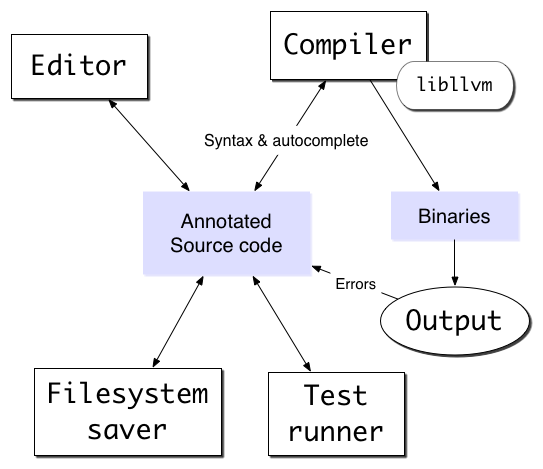
I've been thinking about this idea for awhile, and I'm kind of excited by it. Lets go through some of the details.
I propose we use ShareJS (or something like it) to host the source code & project metadata for a next generation IDE. The central idea is to have a shared data set that any part of the system can read & update.
The sourcecode would be rich text, annotated by the compiler to mark keywords and syntax errors. The editor would use sharejs cursors (when they finally land) to tell the compiler where the cursor is, and the compiler could provide autocomplete suggestions to the client at that edit point.
The best data model for this is probably the new JSON type (not finished yet). The new JSON type will support embedded types and arbitrarily reparenting objects. The source tree will be a tree of rich text nodes. We should probably move all the annotations to an ephemeral part of the document so the compiler's changes aren't versioned with the text, and so if the compiler goes away, there aren't weird lingering artifacts.
Benefits
This would allow all the parts of the IDE to run in their own processes. The editor doesn't need to know or understand the language I'm editing because the compiler is responsible for doing all syntax annotations. The compiler doesn't care what editor or IDE I'm using - the same compiler should work with any IDE. And the whole system doesn't even have to be running on the same machine. If you have several million lines of code, your compiler could be running in a remote data center. So long as it provided the same API, the programmer doesn't care and can use any tools they want.
Because everything is talking over a network, there's no reason to be limited to just have one editor. Pair programming is trivial - just open another editor and connect it to the same shared project. A developer friend of mine complained the other day about how he can't do development work from a chromebook. Why not? So long as you have a network connection to a network with a compiler running somewhere, you should be able to use an editor anywhere. We just need to hook up codemirror or something and we're golden.
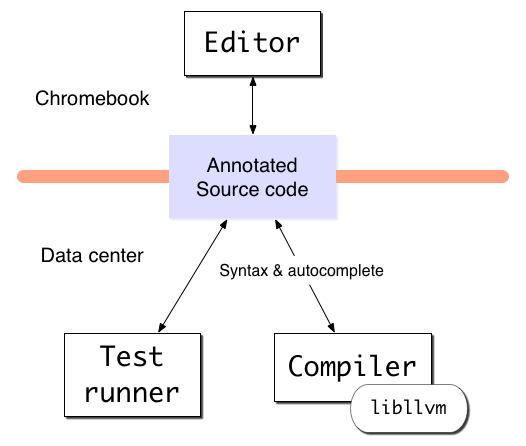
This model also opens the door to much faster incremental compilers. Instead of recompiling a whole file with every change, the compiler could be told about each individual keystroke. This lets the compiler be much smarter - it could recompile just the individual function I'm editing as I type it. Taking full advantage of this will require some serious changes to how modern compilers are written, but there are easy fallbacks to support current compilers.
You could do some other fun things with this too - your project could be simultaneously compiled by different compilers, so you'd know if you did something that was accidentally platform specific. Whenever I write javascript I want my tooling to run my unit tests, collects statistics on the types and then annotate my sourcecode with that data. I want to be able to hover over a variable and be told that 95% of the time its an object with x and y properties (which themselves are numbers). Then I want to be shown stack traces for when thats not true. If we design this well, that tool could be completely standalone. It shouldn't need any editor integration. You should be able to run it when working in visual studio, sublime text or vim.
I think the biggest benefit of all in all of this is to lower the barrier to entry to making new languages. Today every time someone makes a new language we end up out in the cold again. I want all our tooling to move with us as we make new languages!
How do we make this?
This doesn't need any new technologies to exist, but there's obviously a lot of work to be done if we want to make a new kind of IDE, as well as a common interface for all our exiting tools to share. There's a lot of design questions remaining - like do we also expose intermediate compilation steps (like the AST), and if so how?
For now I'm content to keep plodding away on ShareJS and making the new JSON2 type. But this system is bouncing around my head trying to be let out. If you work on IDEs and want to chat about any of this stuff, I'd love to talk. There's a cool thing here that doesn't exist yet. Personally I can't wait to start using it.