The Unix way in an IDE, Part 1
I love the unix philosophy. I want everything I make to be a lot of small tools which compose together to form programs more powerful than any piece on its own.
Shell scripting is the epitome of this. Its a form of programming in a sense - every script does one job, and you plumb them together to perform much more complicated calculations.
For example, the other day I wanted to find out what the biggest files were in redis:
redis/src$ wc *.[ch] | sort -n`
...
2854 t_zset.c
3329 redis.c
3899 sentinel.c
48638 total
Unix pipes let us build programs which have this form:
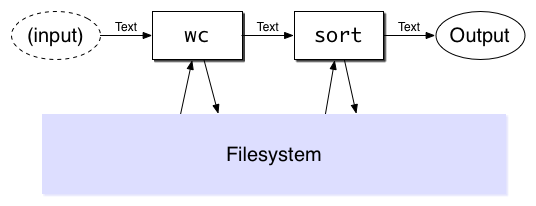
The programs can do anything, and the input & output can be sent to / from the filesystem as well. But we have limited tools for composition. The only way that data can be shared between the processes is in a linear stream - one process's output is another process's input.
Because programs can only communicate this way, to make larger programs requires you to leverage the filesystem. Intermediate state gets saved to the filesystem, then read back in subsequent steps. Not only is this slow, but this way lies madness.
IDEs
As a result, for all their elegence shell scripts tend to get abandoned as our systems get bigger. They're just too awkward. The obvious example where this breaks down is the IDE.
Aside: I love the name IDE because "Integrated development environment" captures the essense of what its trying to do so well. Before IDEs we already had development environments. We made them from a sporradic bunch of tools. The point of an IDE is to compose all the development tools together into something greater than the parts.
All the tools themselves are quite well defined, and have some clear areas of responsibility.
- The editor modifies the source code
- The compiler turns the source code into machine code
- The debugger lets you step through & inspect the program as it runs
.. And so on.
With the right set of composition tools, it should be possible to compose this stuff into an IDE in a sane way. Remember this point - we'll come back to it.
The bad way
For now, lets talk about the simplest possible IDE, which is made up of a source code editor and a compiler, a "Build & Run" button and an output console.
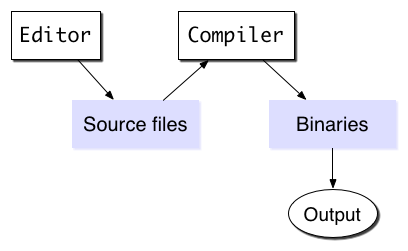
The editor produces source code, which is read back in by the compiler. The compiler produces a binary, which is then run to produce output. Until quite recently, this has been the central abstraction behind an IDE. The IDE would let you configure how the project gets built (which means, what arguments are passed to the compiler). When you hit build, the IDE would shell out to the compiler to do the actual work. There's a beautifully clear separation of concerns here - the compiler doesn't care at all about how the IDE works, and any program which can be compiled with the IDE can be compiled directly by invoking the compiler with the same arguments.
But this is too simplistic to be useful, because a good editor needs to understand your program to help you write it.
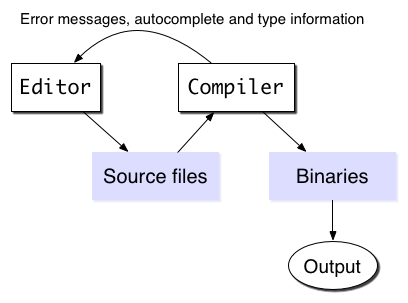
There's lots of information a good editor should display to the user about your program. Following this abstraction, most of that information is known only to the compiler. We want the compiler to share information about:
- Errors and warnings
- Syntax highlighting
- Indexing (so you can jump directly to a function)
- Autocomplete suggestions
And all sorts of other stuff too.
So how do you make this work while still keeping your tools running in separate processes? The old strategy was to rewrite large parts of the compiler in the editor. In VC++ and xCode (<=4), this is exactly what happened. The code to support syntax highlighting, autocomplete and indexing was duplicated in both the compiler and the IDE proper. The format for compilation errors and warnings was formalized so the IDE knew where to put its red squiggly lines.
This is a terrible idea. Anything you have to implement twice will be wrong sometimes. If you have to wait for the compiler to tell you about errors, you'll need to recompile your whole file with every keystroke. It gets much worse when we add in the debugger, profiler, static analysis, unit testing, assembly views and so on.
Better IDEs with linking
The biggest problem is that the parse tree for your program is completely encapsulated by the compiler. The IDE doesn't have access to it - and so it needs to do a lot of work to understand your program that the compiler is already doing.
So the simplest way to attack this problem is the most obvious: Break the compiler into a library and a frontend. This gives your editor, debugger, profiler and everything else access to the data structures which make up the syntax tree. This means that all those tools don't need to re-parse your program.
This is exactly how Xcode 4+ works. One of the biggest reasons LLVM is a big deal is that Clang (the C Language frontend) is foremost a library which can be embedded in your IDE. So now everything can share the code which generates the parse tree.
This isn't good enough.
Its still bloody hard to write good tools on top of this, and it still has terrible performance. I don't want to re-parse the source code in every tool which needs to access it. But I also don't want to deep link all my tools together. I love the unix way, where everything is a simple composable program.
Sharing state
I think the real answer is to share state between the editor, the compiler, the IDE and any other tools which need to understand my program. I want an IDE where the editor doesn't even understand the programming language I'm editing. But this is a topic for part 2!