Reverse engineering Apple Dictionaries
Edit: Part 2 is up
I've spent this morning doing some cursory reverse engineering to access the dictionaries on my mac laptop. I'll post some code soon to access them, but in the meantime here's the story of some of the process I went through to recover that data.
Because of a ridiculous series of events, I'm going to be running a 45 minute workshop on Friday on regular expressions to non-technical people. I lay in bed this morning thinking about how to teach it - I think I'm going to give them shell access to my laptop (through putty) and find a few files they can get hands-on experience running grep over. Well then, what files? Honestly, when do I use grep? I parse log files. I sometimes search through text files (I could give them Project Gutenburg's copy of Alice in Wonderland). But by far most useful thing of all is grepping over words in the dictionary.
Why? Well, certainly not to cheat at scrabble. Thats for sure.
MacOS, like all good UNIXes has a words list in /usr/share/dict/words. Its a list of all words in the (out of copyright) Webster International from 1934. It has 235,886 words in it - most of which nobody has ever heard of. You don't know what they mean and you can't even find them in normal dictionaries.
Here's the first 10 words that aren't proper nouns:
$ grep -v '^[A-Z]' /usr/share/dict/words | head -n10
a
aa
aal
aalii
aam
aardvark
aardwolf
aba
abac
abaca
I swear they're almost all made up words - I only know what 2 of those 10 words mean (a and aardvark). What the hell is an aardwolf? Even if words with friends accepts that, I'm going to need a cover story.
I could clearly use a better word list.
Conveniently, MacOS comes with a Dictionary app, which contains 21 dictionaries including the Oxford Dictionary of English (2013). The word list in the Dictionary app is probably vastly better most of the time - and I already have a copy on my laptop. I don't even need to pirate it.
So how can we get the word list out so I can grep for things? Some googling shows that the dictionaries are all stored in /Library/Dictionary.
They're resource bundles - so even though it looks like a file in Finder, its actually a directory. (You have to right-click -> Show Package Contents to browse inside in Finder). So whats inside? How is it stored? Maybe a nice SQLite database?
$ ls -lS /Library/Dictionaries/Oxford\ Dictionary\ of\ English.dictionary/Contents/
total 57256
-rw-r—r— 1 root wheel 22456991 10 Sep 2014 Body.data
-rw-r—r— 1 root wheel 5416344 10 Sep 2014 KeyText.index
-rw-r—r— 1 root wheel 4153416 10 Sep 2014 KeyText.data
-rw-r—r— 1 root wheel 405568 10 Sep 2014 EntryID.data
-rw-r—r— 1 root wheel 242564 10 Sep 2014 EntryID.index
…
.body and .index? What are those? Unfortunately, its some custom binary format.
$ file *.data *.index
Body.data: data
EntryID.data: data
KeyText.data: data
EntryID.index: data
KeyText.index: data
So, how do we get the data out?
Before reading down, spend a few seconds thinking about how you would do it. Here's my list of things we could try.
- See if someone else knows what those files are. If so, maybe they've written tools to extract their contents?
- Reverse engineer the binary format in the files.
- Look for official / unofficial APIs to query the data files. The dictionary app is clearly reading these files - so it has functions to read this stuff. If we could call those functions, we wouldn't have to write our own.
- Hook an automation script of some sort to drive the Dictionary app, and go down the list of all words through the UI.
Its kind of fun - each of these requires totally different skills. Except for the first, they're all guaranteed to work. Isn't that cool? In a sense, the data goes from the data & index files, via an API to the app and then shown to the user. Anywhere along that chain we can hook our own code in and get a copy of the data.
As for 1, nobody else has published information on the file format. Either nobody has reverse engineered it or nobody is talking.
There's an official API to access the dictionary. But its super limited - Apple only exposes two functions, and one of them is useless (it pops up a dictionary definition window). The other one looks for a definition at a specified place in a string. We could probably combine that with the giant word list to check if a word is in the new dictionary - but I bet the 1934 word list is missing lots of modern words.
I haven't finished reverse engineering the data. I hope to put up more information once I have. For now, here's some notes:
Binary format
I first tried reverse engineering the binary files. I can't find any words in them at all - they're either compressed or encrypted, or they're using a fancy data structure for fast queries.
Apple has documentation on making dictionaries. I downloaded the Dictionary Development Kit to see how the dictionaries were made - and I hoped maybe it would have extraction tools. No such luck on the extraction tools, but I learned an awful lot about the process. Dictionaries can be compressed and encrypted. At a guess, the dictionary looks like its broken up into a file containing the entries themselves in some compressed XML format, and another file which indexes in to offsets in the entry set. The index is probably a Trie.
There's references to compression and encryption in Apple's build_dict script. I wanted to know if the index is compressed / encrypted. If so, I'll need to find the compression method and keys. Here's a histogram of byte values in the data file. (This graphs byte value from 0-255 along the bottom vs the number of times that byte value appears in the file):
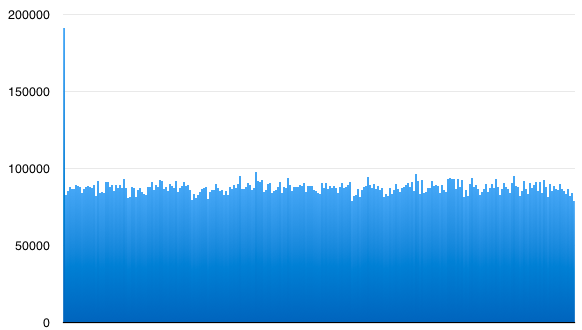
The data file is clearly compressed / encrypted - thats why all byte values appear with about the same frequency. (But, twice as many zeros as anything else!) I suspect its just compressed. There's lots of zeros because the entries are compressed individually, and then padded out to some power-of-two size or something.
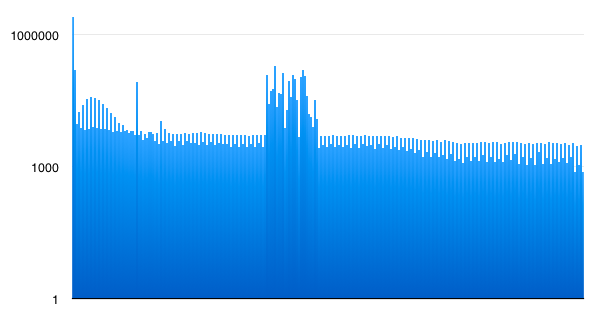
And here's a histogram of the byte values in the index file:
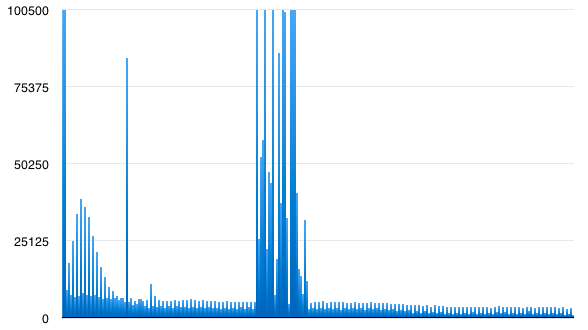
Look at how different they are!
The index has values all over the place! I clipped the top of the chart so you can see the small values at all. You can read it better on a log scale, but I think its the shape of the chart thats interesting - not the absolute values. Some features: Note how lower values are more frequent than high values. Also even numbers are more common than odd ones. At a guess, the mountain in the middle looks like it approximately corresponds to letters in the ASCII range, even though there's no instances of more than a few english letters in a row in the file. All this is exactly what I would expect for a sparse trie serialized to a file.
{kind=link}
I suspect the .index file is an index listing location & sizes of chunks in the data file. And I suspect if I went looking, I'd find the chunks contain compressed dictionary entries. That said, I don't really care about the entries - I just want the word list. If I can just get the keys out of the index, I win. So that might be pretty easy.
Libraries
The actual tools to make the binary dictionary files are (sadly) compiled C programs. I took a look at build_reference_index in the dictionary dev kit using MacDependancy. It calls some undocumented methods in the Dictionary Services framework like _IDXBuildIndexWithRecords. (OOoooh super promising!) It doesn't link to any encryption or compression code directly. The dictionary services framework does though - it calls compress in zlib (gzip) and it calls some crypto code in Security.framework.
Following the trail to DictionaryServices.framework, it looks like there's a whole lot of functions exposed for the dictionary app. Using these undocumented methods is probably the best way to access the data:
- These methods will probably be more stable than the dictionary file format (although I would be surprised if either changed anytime soon).
- As my old supervisor used to say, 2 weeks in the lab will save you 5 minutes in the library. Calling these functions directly will probably be much faster than reverse engineering Apple's trie implementation.
That said, reversing the trie might be more fun.
I'll do a followup post if/when I actually get the data out. Its been a fun little excursion, and the whole thing looks pretty easy. I probably spent more time writing this blog post than actually trawling through the data itself. I find it so interesting pouring through other engineers' shipped work. There's always so much to learn.
If anyone is curious how I generated those histograms, I used the coffeescript REPL and this code:
b = fs.readFileSync 'KeyText.index'
f = (0 for [0...256])
f[c]++ for c in b; f
console.log(x) for x in f; null
Then I copy-pasted the list of values into Numbers and hit 'Chart'.