This is a repost from my old tumblr blog from March 19
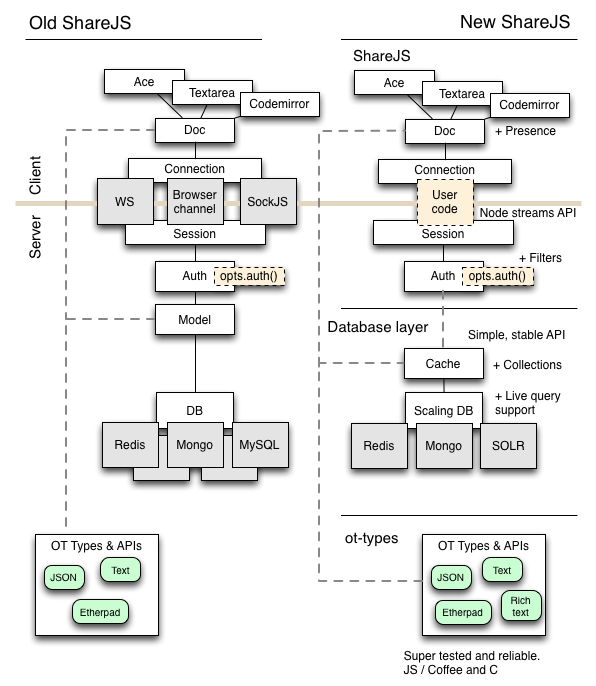
A month ago I got hired by Lever and moved over to San Francisco. We're building an applicant tracking system for hiring. Its a realtime web app built on top of Derby and Racer, which is a web framework written by the company's cofounders.
Racer doesn't do proper OT and it doesn't scale. Over the next few months, I'm going to refactor and rewrite big chunks of ShareJS so we can use it underneath racer to keep data in sync between the browser and our servers. I'm going to refactor ShareJS into a few modules (long overdue), add live queries to ShareJS and make the database layer support scaling.
I want feedback on this before I start. I will break things, but I think its worth it in the long term.
So, without further ado, here's the master plan:
Standardized OT Library
First, ShareJS's OT types are written to a simple API and don't depend on any external services. I'm going to pull them out into their own project, akin to libOT.
The types here should be super stable and fast, and preferably written in multiple languages.
I considered adding some simple, reusable OT management code in there too, but by the time I pared OT down until I had something reusable, it was just a for loop.
I'm not sure where the text & JSON API wrappers should go. The wrappers are generally useful, but not coded in a particularly reusable way.
Scalable database backend
Next, we need a scalable version of ShareJS's database code. I want to pull out ShareJS's database code and make it support scaling the server across multiple machines.
I also want to add:
- Collections: Documents will be scoped by collection. I expect collections to map to SQL tables, mongodb collections or couchdb databases. Collections seem to be a standard, useful thing.
- Live queries: I want to be able to issue a query saying "get me all docs in the profiles collection with age > 50". The result set should update in realtime as documents are added & removed from that set. This should also work with paginated requests. I don't want to invent my own query language - I'll just use whatever native format the database uses. (SQL select statements, couchdb views, mongo find() queries, etc).
- Snapshot update hooks: For example, I want to be able to issue a query to a full-text search database (like SOLR) and reuse the same live query mechanism. I imagine this working via a post-update hook that the application can use to update SOLR. As a first pass, I'll poll all outstanding queries against the database when documents are updated, but I can optimise for certain common use cases down the track.
I want to get the API here stable first and let the implementation grow in complexity as we need it to be more scalable and reliable. At first, this code will route all messages through a single redis server. Later I want to set it up with a redis slave for automatic failover and make the server shard between multiple DB instances using consistant hashing of document IDs or something.
I'm nervous about how the DB code and the operational transform algorithm will work. If the DB backend doesn't understand OT, the API will have to be strongly tied to ShareJS's model code and harder to reuse. But if I make it understand OT and subsume ShareJS's model code, it makes the DB code much harder to adapt to work with other databases (you'll need to rewrite all that code!). I really love the state of model.coffee in ShareJS at the moment, though it took me 2 near complete rewrites to get to that point.
I would also like to make a trivial in-memory implementation for examples and for testing. Once I have two implementations and a test suite, it should be possible to rewrite this layer on top of Hadoop or AWS or whatever.
ShareJS code
Whats left for ShareJS?
ShareJS's primary responsibility is to let you access the OT database in a web browser or nodejs client in a way thats secure & safe.
It will (still) have these components:
- Auth function for limiting reading & writing. I want to extend this for JSON documents to make it easy to restrict / trim access to certain parts of some documents.
- Session code to manage client sessions. All the protocol stuff thats in session.coffee. I want to rewrite / refactor this to use NodeJS's new streams.
- Presence, although this will require some rethinking to work with the new database backend stuff.
- A simple API that lets you tell the server when it has a new client, and pass messages for it. I'm sick of all the nonsense around socket.io, browserchannel, sockjs, etc so I want to just make it the user's problem. Again, this will use the new streams API. This also makes it really easy for applications to send messages to their server that don't have anything to do with OT.
- Equivalent connection code on the client, currently in client/connection.coffee.
- Client-side OT code, currently in client/doc.coffee.
- Build script to bundle up & minify the client and required OT types for the browser. I want to rewrite this in Make. (Sorry windows developers).
- Tests. It looks like nodeunit is no longer actively maintained, so it might time to port the tests to a different framework. (Suggestions? What does everybody use these days?)
ShareJS has slowly become a grab bag of other stuff that I like. I'm not sure whether all this stuff should stay in ShareJS or what.
There is:
- The examples. These will wire ShareJS up with browserchannel and express. The examples will add a few dependancies that ShareJS won't otherwise have.
- The different database backends. Unless someone makes an adapter for my new database code, these are all going to break. Sorry.
- Browser binding for textareas, ace and codemirror
- All the ongoing etherpad work. I met a bunch of etherpad & etherpad lite developers at an event last week, and they were awesome. Super happy this is happening.
Thoughts
Thats the gist of the redesign. Some thoughts:
I hate making ShareJS more complicated, but at the same time I think its important to make it actually useful. People need to scale their servers and they need to be able to build complex applications on top of all this stuff. I love how ShareJS's entire server is basically encapsulated in one file, and it'll be a pity to lose that.
This change will break existing code. Sorry. The current DB adapters will break, and putting documents in collections will change APIs all the way though ShareJS.
I'm still not entirely sure how this redesign will interact with my C port of ShareJS. Before I realised how integral ShareJS would be to my current work, I was intending to finish working on my C implementation next. For now, I guess that'll take a back seat. (In exchange, I'll be working on this stuff while at work, and not just on weekends.)
This design allows some nice application features. For example, the auth stuff can much more easily enforce schemas for documents. You could enforce that everything in the 'code' collection has type 'text', everything in the 'projects' collection is JSON (with a particular structure) and items in the 'profiles' directory are only editable by user who owns the profile. You could probably do that before, but it was a bit more subtle.
As I said above, I'm not sure where the line should be drawn between the DB project and the model. If they're two separate projects, they should have a very clear separation of concerns. I'm really trying to build a DB wrapper that provides the API that I want databases to provide directly, in a scalable way. However, that idea is entangled with the OT and presence functionality. What a mess.
I want feedback on all this stuff. I know a lot of people are building cool stuff with ShareJS, or want to. Do these plans make your lives better or worse? Should we keep the current simple incantation of ShareJS around? If I'm taking the time to rip the guts out of ShareJS, what else would you like to see changed? How do these ideas interact with the etherpad interaction work?
Thanks!